Method
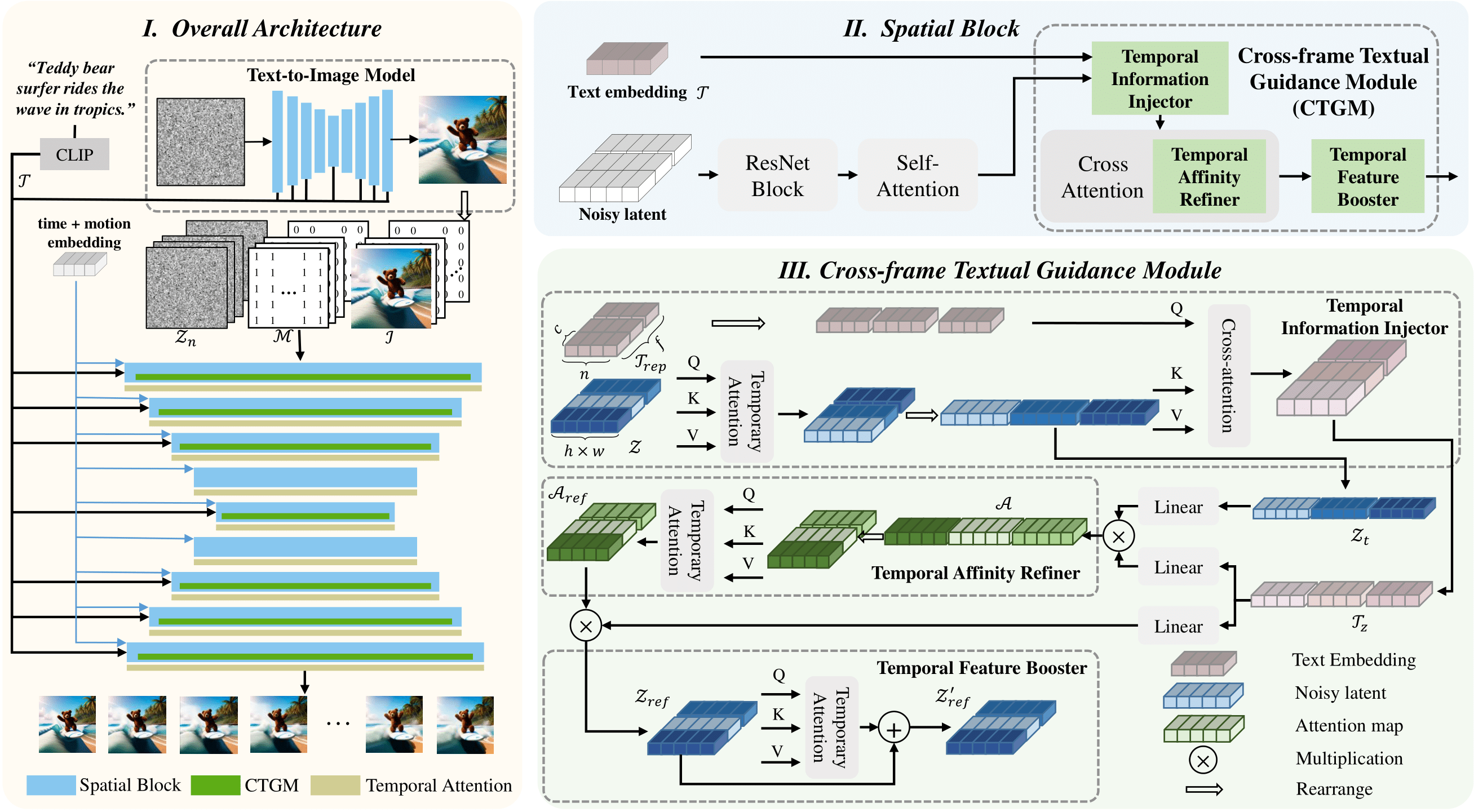
Synthesizing motion-rich and temporally consistent videos remains a challenge in artificial intelligence, especially when dealing with extended durations. Existing text-to-video (T2V) models commonly employ spatial cross-attention for text control, equivalently guiding different frame generations without frame-specific textual guidance. Thus, the model's capacity to comprehend the temporal logic conveyed in prompts and generate videos with coherent motion is restricted. To tackle this limitation, we introduce FancyVideo, an innovative video generator that improves the existing text-control mechanism with the well-designed Cross-frame Textual Guidance Module (CTGM). Specifically, CTGM incorporates the Temporal Information Injector (TII), Temporal Affinity Refiner (TAR), and Temporal Feature Booster (TFB) at the beginning, middle, and end of cross-attention, respectively, to achieve frame-specific textual guidance. Firstly, TII injects frame-specific information from latent features into text conditions, thereby obtaining cross-frame textual conditions. Then, TAR refines the correlation matrix between cross-frame textual conditions and latent features along the time dimension. Lastly, TFB boosts the temporal consistency of latent features. Extensive experiments comprising both quantitative and qualitative evaluations demonstrate the effectiveness of FancyVideo. Our approach achieves state-of-the-art T2V generation results on the EvalCrafter benchmark and facilitates the synthesis of dynamic and consistent videos.
768 × 768
1024 × 768
768 × 1024
1024 × 1024
Realcartoon3d
Toonyou
PixarsRendman
A woman wearing denim jacket and cowboy hat
@misc{feng2024fancyvideodynamicconsistentvideo,
title={FancyVideo: Towards Dynamic and Consistent Video Generation via Cross-frame Textual Guidance},
author={Jiasong Feng and Ao Ma and Jing Wang and Bo Cheng and Xiaodan Liang and Dawei Leng and Yuhui Yin},
year={2024},
eprint={2408.08189},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2408.08189},
}